Mock My Draft
A web app that archives, analyzes, and presents grades for historical NFL drafts.
The Problem
NFL draft history is scattered across many sources, making it difficult for fans, analysts, and enthusiasts to compare how teams performed over time. There was no centralized place to explore historical drafts, view draft grades from different analysts, and understand long-term team performance patterns.
My Role
I built Mock My Draft as a full-stack web application from scratch. I designed and implemented the data architecture for storing and retrieving historical draft data, created interactive visualizations for exploring draft trends, and built a user interface that makes navigating decades of NFL draft history intuitive and engaging.
Tech Stack
-
React: Chosen for its component-based architecture, which made building the complex, interactive UI manageable. The ability to reuse components across different views of the data was essential.
-
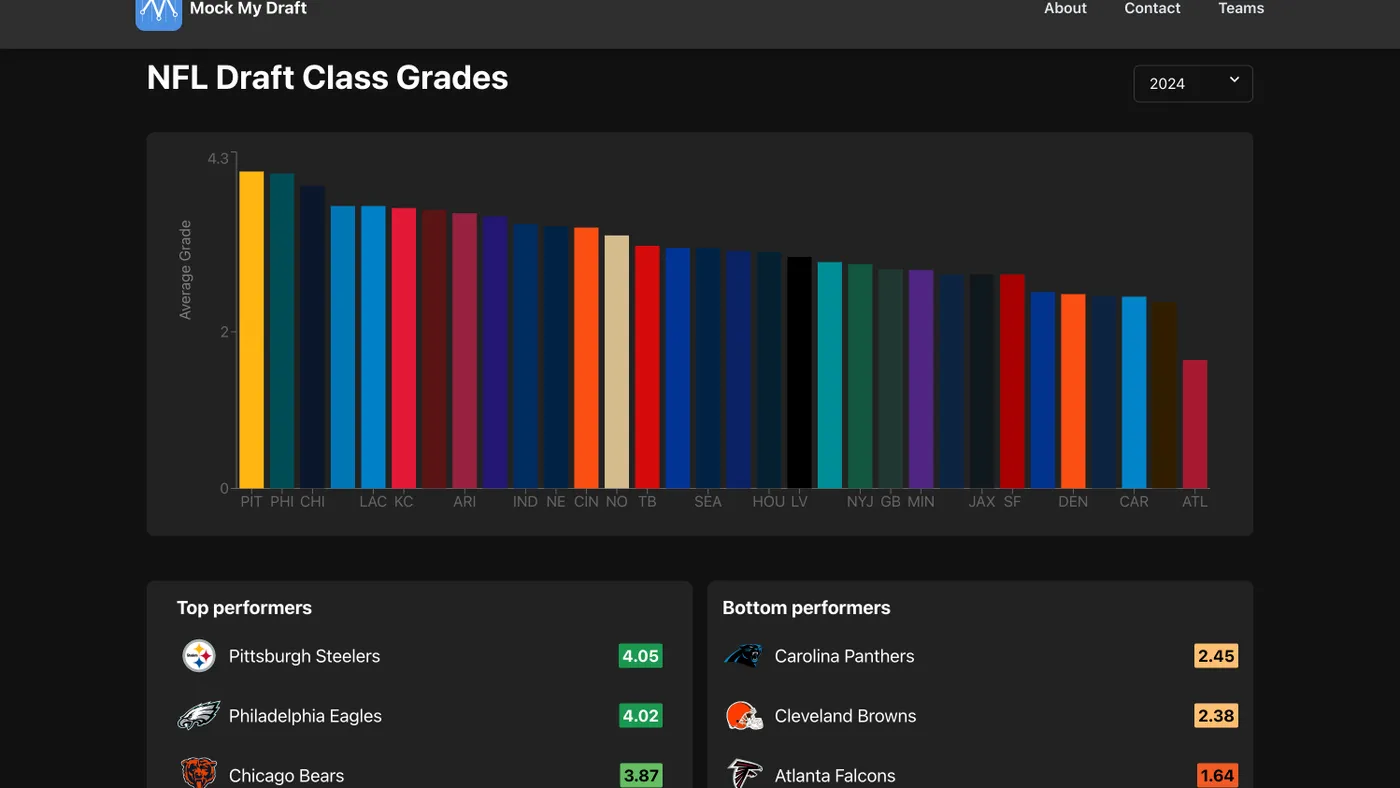
D3.js: Used for creating rich, interactive data visualizations. Draft data visualization requires the flexibility that D3 provides — from simple bar charts comparing team performance to more complex trellis layouts showing draft trends across multiple years.
-
Node.js: Provides the backend API and data processing pipeline. Node’s asynchronous I/O handling was crucial for efficiently serving large datasets of draft history and grades.
Key Features
-
Historical Draft Archive: Comprehensive database of historical NFL drafts going back decades, with searchable team, player, and pick data
-
Draft Grade Aggregation: Draft grades are sourced from various publications around the web and normalized into a consistent format for comparison across analysts and years.
-
Interactive Visualizations: Interactive charts and graphs built with D3.js let users explore draft trends, compare team performance over time, and analyze draft position patterns with dynamic filtering.
-
Team Comparison Tools: Users can compare multiple teams’ draft performance side by side, viewing aggregated grades and trends across different time periods to understand long-term franchise strategy.
Lessons Learned
Building Mock My Draft reinforced the importance of thoughtful data modeling when working with historical sports data. I learned that the data pipeline is the most critical component — going from unstructured articles to structured data with normalized grades using rules-based scraping was technically complex, and I’m now exploring LLM-based parsers as a more robust replacement.
I also discovered that getting clean, normalized data from messy sources is the core challenge — the data pipeline really is the product itself, and investing time in robust data transformation pays dividends throughout the application.